Shilin Lu

I am a third-year Ph.D. student at the College of Computing and Data Science, Nanyang Technological University (NTU), Singapore, where I have the privilege of being supervised by Dr. Yanzhu Liu and Prof. Adams Wai-Kin Kong.
Prior to this, I earned my Master’s degree at School of Electrical and Electronic Engineering, NTU, under the guidance of Dr. Siyuan Yang and Prof. Alex Chichung Kot. I completed my Bachelor’s degree at Shandong University (SDU), where I was fortunate to be mentored by Prof. Chengyou Wang, whose meticulous and dedicated guidance laid the foundation for my future research endeavors.
Research Interests
In the past, my work focused on guiding generative models through test-time interventions or fine-tuning to expand or reshape their capabilities. With test-time interventions, I explored ways to influence the sampling process so that general text-to-image models could adapt to new tasks (e.g., text-driven image editing, object insertion, drag-based editing). With fine-tuning, I focused on adjusting models‘ internal concept representations to ensure that generated outputs better align with our expectations.
Now, my interests are extending toward video generation and world models. I am curious about how these models learn, imagine, and reason about dynamic scenes and evolving environments, and how we might guide them with the same clarity and control.
Taken together, these explorations reflect a shared pursuit: understanding how to shape the abilities and internal representations of generative models so they can create and interpret the worlds we ask of them with greater precision and coherence.
News
| Jul 5, 2025 | One paper is accepted by ACMMM 2025. |
|---|---|
| May 1, 2025 | One paper is accepted by ICML 2025. |
| Jan 23, 2025 | One paper is accepted by ICLR 2025. |
| Feb 27, 2024 | One paper is accepted by CVPR 2024. |
| Jul 21, 2023 | One paper is accepted by ICCV 2023. |
Selected Publications
2025
- ICLR 2025
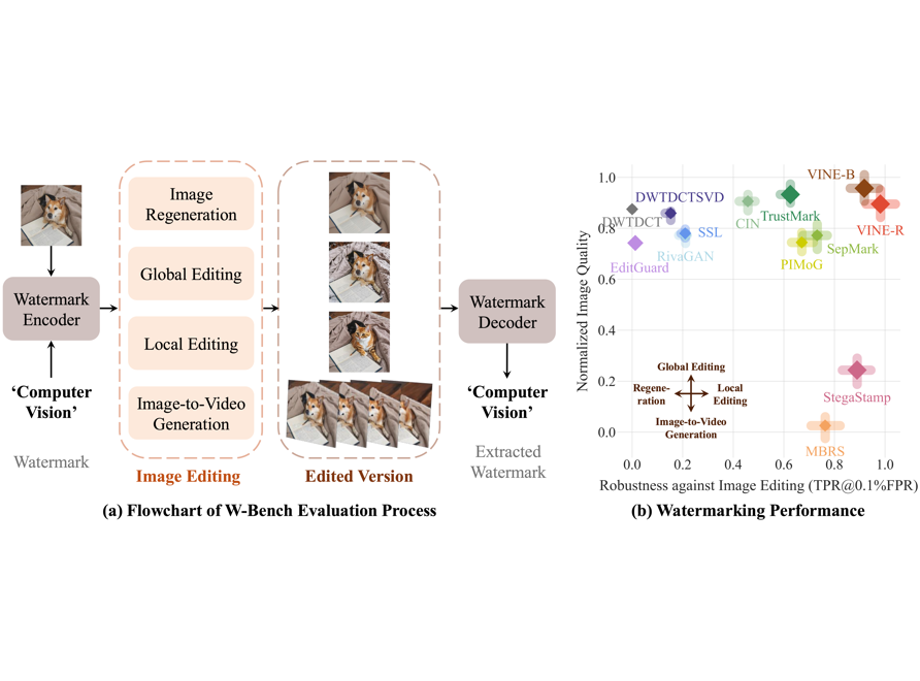 Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to AdvancesInternational Conference on Learning Representations (ICLR), 2025
Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to AdvancesInternational Conference on Learning Representations (ICLR), 2025







2024


2023
- ICCV 2023
 TF-ICON: Diffusion-Based Training-Free Cross-Domain Image CompositionIEEE/CVF International Conference on Computer Vision (ICCV), 2023
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image CompositionIEEE/CVF International Conference on Computer Vision (ICCV), 2023

