Publications
2025
- ICLR 2025
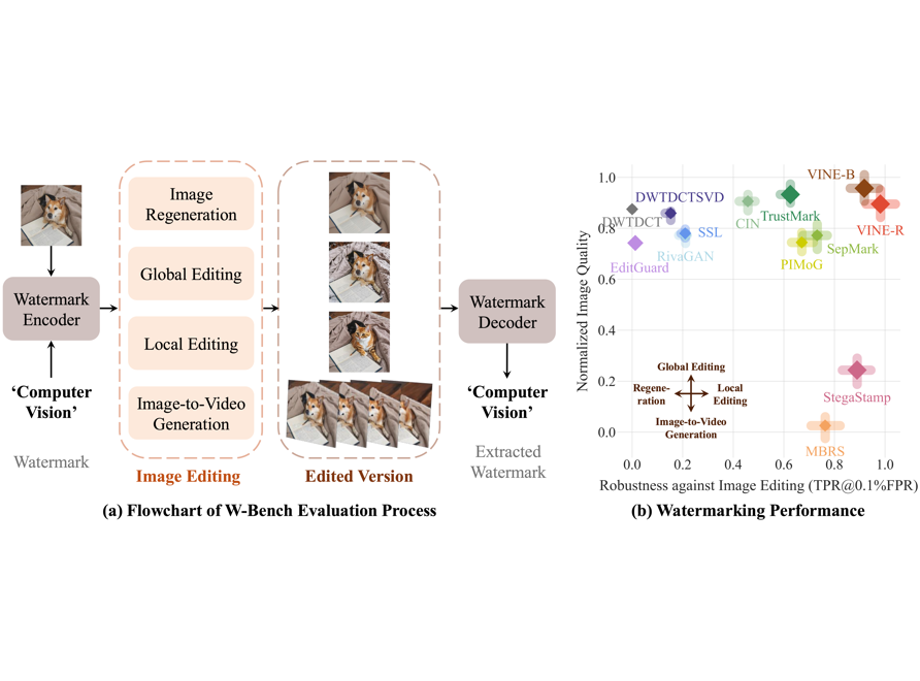 Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to AdvancesShilin Lu, Zihan Zhou, Jiayou Lu, Yuanzhi Zhu, and Adams Wai-Kin KongInternational Conference on Learning Representations (ICLR), 2025
Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to AdvancesShilin Lu, Zihan Zhou, Jiayou Lu, Yuanzhi Zhu, and Adams Wai-Kin KongInternational Conference on Learning Representations (ICLR), 2025Current image watermarking methods are vulnerable to advanced image editing techniques enabled by large-scale text-to-image models. These models can distort embedded watermarks during editing, posing significant challenges to copyright protection. In this work, we introduce W-Bench, the first comprehensive benchmark designed to evaluate the robustness of watermarking methods against a wide range of image editing techniques, including image regeneration, global editing, local editing, and image-to-video generation. Through extensive evaluations of eleven representative watermarking methods against prevalent editing techniques, we demonstrate that most methods fail to detect watermarks after such edits. To address this limitation, we propose VINE, a watermarking method that significantly enhances robustness against various image editing techniques while maintaining high image quality. Our approach involves two key innovations: (1) we analyze the frequency characteristics of image editing and identify that blurring distortions exhibit similar frequency properties, which allows us to use them as surrogate attacks during training to bolster watermark robustness; (2) we leverage a large-scale pretrained diffusion model SDXL-Turbo, adapting it for the watermarking task to achieve more imperceptible and robust watermark embedding. Experimental results show that our method achieves outstanding watermarking performance under various image editing techniques, outperforming existing methods in both image quality and robustness.
- ACMMM 2025
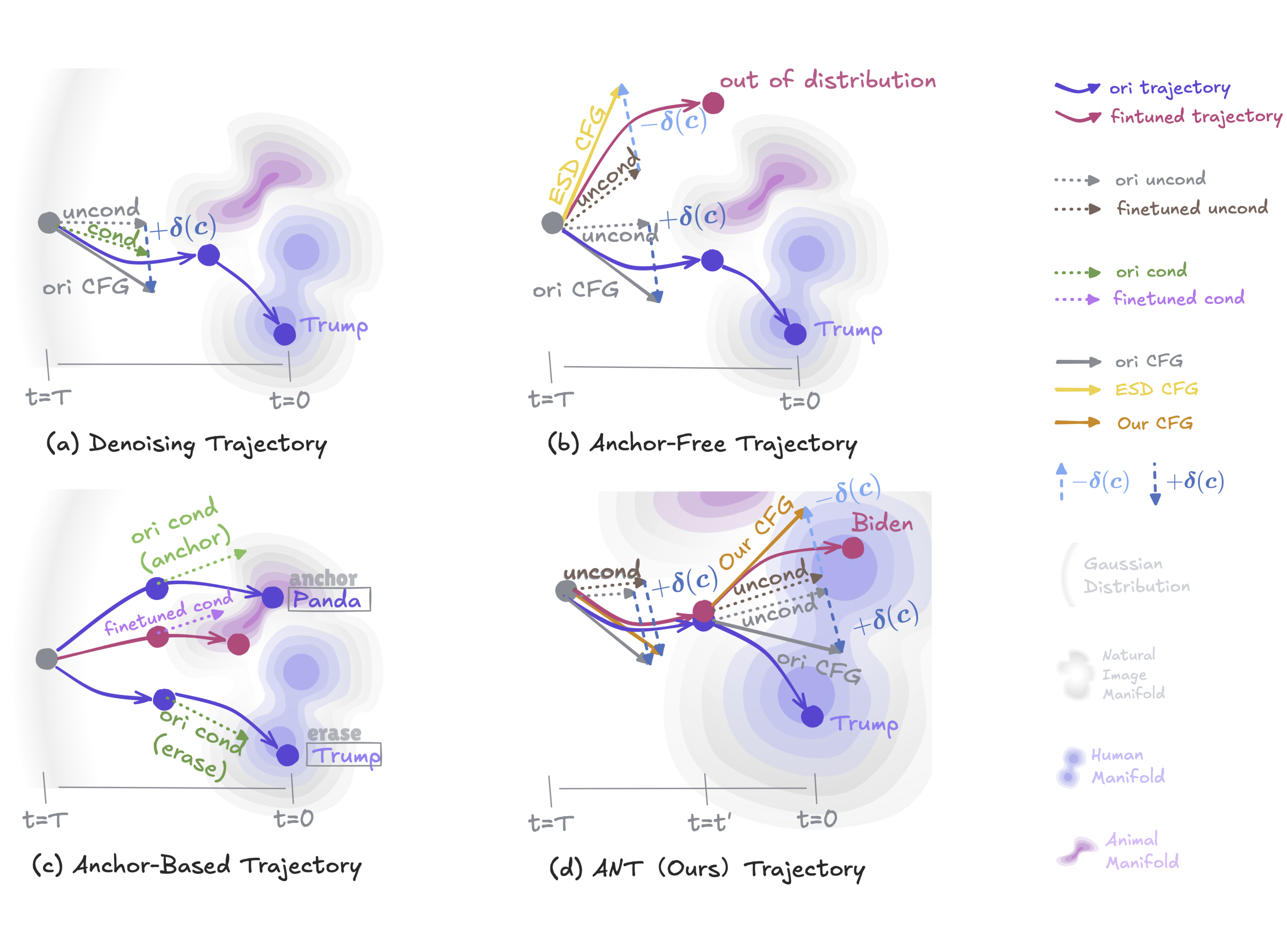 Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted ConceptsLeyang Li*, Shilin Lu*, Yan Ren, and Adams Wai-Kin Kong(*: Equal Contribution)ACM International Conference on Multimedia (ACMMM), 2025
Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted ConceptsLeyang Li*, Shilin Lu*, Yan Ren, and Adams Wai-Kin Kong(*: Equal Contribution)ACM International Conference on Multimedia (ACMMM), 2025Ensuring the ethical deployment of text-to-image models requires effective techniques to prevent the generation of harmful or inappropriate content. While concept erasure methods offer a promising solution, existing finetuning-based approaches suffer from notable limitations. Anchor-free methods risk disrupting sampling trajectories, leading to visual artifacts, while anchor-based methods rely on the heuristic selection of anchor concepts. To overcome these shortcomings, we introduce a finetuning framework, dubbed ANT, which Automatically guides deNoising Trajectories to avoid unwanted concepts. ANT is built on a key insight: reversing the condition direction of classifier-free guidance during mid-to-late denoising stages enables precise content modification without sacrificing early-stage structural integrity. This inspires a trajectory-aware objective that preserves the integrity of the early-stage score function field, which steers samples toward the natural image manifold, without relying on heuristic anchor concept selection. For single-concept erasure, we propose an augmentation-enhanced weight saliency map to precisely identify the critical parameters that most significantly contribute to the unwanted concept, enabling more thorough and efficient erasure. For multi-concept erasure, our objective function offers a versatile plug-and-play solution that significantly boosts performance. Extensive experiments demonstrate that ANT achieves state-of-the-art results in both single and multi-concept erasure, delivering high-quality, safe outputs without compromising the generative fidelity. Code is available at https://github.com/lileyang1210/ANT
- ICML 2025
 EraseAnything: Enabling Concept Erasure in Rectified Flow TransformersDaiheng Gao, Shilin Lu, Shaw Walters, Wenbo Zhou, Jiaming Chu, and 6 more authorsInternational Conference on Machine Learning (ICML), 2025
EraseAnything: Enabling Concept Erasure in Rectified Flow TransformersDaiheng Gao, Shilin Lu, Shaw Walters, Wenbo Zhou, Jiaming Chu, and 6 more authorsInternational Conference on Machine Learning (ICML), 2025Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (e.g., SD v1.4). In this work, we introduce EraseAnything, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
- ICLR 2026
 Does FLUX Already Know How to Perform Physically Plausible Image Composition?Shilin Lu*, Zhuming Lian*, Zihan Zhou, Shaocong Zhang, Chen Zhao, and 1 more author(*: Equal Contribution)Preprint, 2025
Does FLUX Already Know How to Perform Physically Plausible Image Composition?Shilin Lu*, Zhuming Lian*, Zihan Zhou, Shaocong Zhang, Chen Zhao, and 1 more author(*: Equal Contribution)Preprint, 2025Image composition aims to seamlessly insert a user-specified object into a new scene, but existing models struggle with complex lighting (e.g., accurate shadows, water reflections) and diverse, high-resolution inputs. Modern text-to-image diffusion models (e.g., SD3.5, FLUX) already encode essential physical and resolution priors, yet lack a framework to unleash them without resorting to latent inversion, which often locks object poses into contextually inappropriate orientations, or brittle attention surgery. We propose SHINE, a training-free framework for Seamless, High-fidelity Insertion with Neutralized Errors. SHINE introduces manifold-steered anchor loss, leveraging pretrained customization adapters (e.g., IP-Adapter) to guide latents for faithful subject representation while preserving background integrity. Degradation-suppression guidance and adaptive background blending are proposed to further eliminate low-quality outputs and visible seams. To address the lack of rigorous benchmarks, we introduce ComplexCompo, featuring diverse resolutions and challenging conditions such as low lighting, strong illumination, intricate shadows, and reflective surfaces. Experiments on ComplexCompo and DreamEditBench show state-of-the-art performance on standard metrics (e.g., DINOv2) and human-aligned scores (e.g., DreamSim, ImageReward, VisionReward). Code and benchmark will be publicly available upon publication.
- ICLR 2026
 DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag EditingZihan Zhou*, Shilin Lu*, Shuli Leng, Shaocong Zhang, Zhuming Lian, and 2 more authors(*: Equal Contribution)Preprint, 2025
DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag EditingZihan Zhou*, Shilin Lu*, Shuli Leng, Shaocong Zhang, Zhuming Lian, and 2 more authors(*: Equal Contribution)Preprint, 2025Drag-based image editing has long suffered from distortions in the target region, largely because the priors of earlier base models, Stable Diffusion, are insufficient to project optimized latents back onto the natural image manifold. With the shift from UNet-based DDPMs to more scalable DiT with flow matching (e.g., SD3.5, FLUX), generative priors have become significantly stronger, enabling advances across diverse editing tasks. However, drag-based editing has yet to benefit from these stronger priors. This work proposes the first framework to effectively harness FLUX’s rich prior for drag-based editing, dubbed DragFlow, achieving substantial gains over baselines. We first show that directly applying point-based drag editing to DiTs performs poorly: unlike the highly compressed features of UNets, DiT features are insufficiently structured to provide reliable guidance for point-wise motion supervision. To overcome this limitation, DragFlow introduces a region-based editing paradigm, where affine transformations enable richer and more consistent feature supervision. Additionally, we integrate pretrained open-domain personalization adapters (e.g., IP-Adapter) to enhance subject consistency, while preserving background fidelity through gradient mask-based hard constraints. Multimodal large language models (MLLMs) are further employed to resolve task ambiguities. For evaluation, we curate a novel Region-based Dragging benchmark (ReD Bench) featuring region-level dragging instructions. Extensive experiments on DragBench-DR and ReD Bench show that DragFlow surpasses both point-based and region-based baselines, setting a new state-of-the-art in drag-based image editing. Code and datasets will be publicly available upon publication.
- Preprint
 Revoking Amnesia: RL-based Trajectory Optimization to Resurrect Erased Concepts in Diffusion ModelsDaiheng Gao, Nanxiang Jiang, Andi Zhang, Shilin Lu, Yufei Tang, and 3 more authorsPreprint, 2025
Revoking Amnesia: RL-based Trajectory Optimization to Resurrect Erased Concepts in Diffusion ModelsDaiheng Gao, Nanxiang Jiang, Andi Zhang, Shilin Lu, Yufei Tang, and 3 more authorsPreprint, 2025Concept erasure techniques have been widely deployed in T2I diffusion models to prevent inappropriate content generation for safety and copyright considerations. However, as models evolve to next-generation architectures like Flux, established erasure methods (\textite.g., ESD, UCE, AC) exhibit degraded effectiveness, raising questions about their true mechanisms. Through systematic analysis, we reveal that concept erasure creates only an illusion of “amnesia": rather than genuine forgetting, these methods bias sampling trajectories away from target concepts, making the erasure fundamentally reversible. This insight motivates the need to distinguish superficial safety from genuine concept removal. In this work, we propose \textbfRevAm (\underlineRevoking \underlineAmnesia), an RL-based trajectory optimization framework that resurrects erased concepts by dynamically steering the denoising process without modifying model weights. By adapting Group Relative Policy Optimization (GRPO) to diffusion models, RevAm explores diverse recovery trajectories through trajectory-level rewards, overcoming local optima that limit existing methods. Extensive experiments demonstrate that RevAm achieves superior concept resurrection fidelity while reducing computational time by 10×, exposing critical vulnerabilities in current safety mechanisms and underscoring the need for more robust erasure techniques beyond trajectory manipulation.
- ICLR 2026
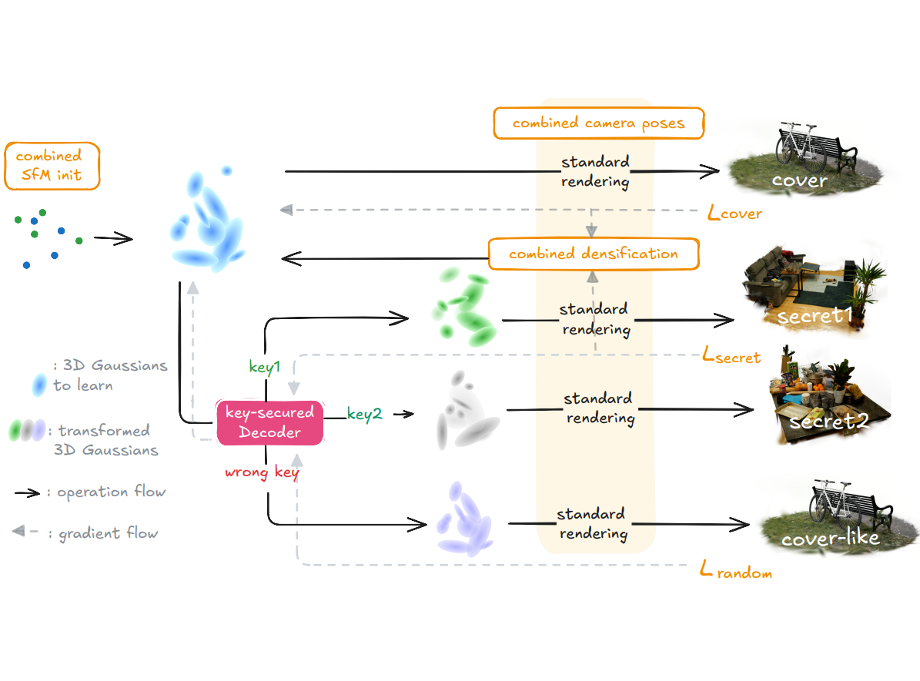 All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian SplattingYan Ren, Shilin Lu, and Adams Wai-Kin KongPreprint, 2025
All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian SplattingYan Ren, Shilin Lu, and Adams Wai-Kin KongPreprint, 2025Recent advances in 3D Gaussian Splatting (3DGS) have revolutionized scene reconstruction, opening new possibilities for 3D steganography by hiding 3D secrets within 3D covers. The key challenge in steganography is ensuring imperceptibility while maintaining high-fidelity reconstruction. However, existing methods often suffer from detectability risks and utilize only suboptimal 3DGS features, limiting their full potential. We propose a novel end-to-end key-secured 3D steganography framework (KeySS) that jointly optimizes a 3DGS model and a key-secured decoder for secret reconstruction. Our approach reveals that Gaussian features contribute unequally to secret hiding. The framework incorporates a key-controllable mechanism enabling multi-secret hiding and unauthorized access prevention, while systematically exploring optimal feature update to balance fidelity and security. To rigorously evaluate steganographic imperceptibility beyond conventional 2D metrics, we introduce 3D-Sinkhorn distance analysis, which quantifies distributional differences between original and steganographic Gaussian parameters in the representation space. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both cover and secret reconstruction while maintaining high security levels, advancing the field of 3D steganography.







2024
- CVPR 2024
 Mace: Mass Concept Erasure in Diffusion ModelsShilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin KongIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Mace: Mass Concept Erasure in Diffusion ModelsShilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin KongIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024The rapid expansion of large-scale text-to-image diffusion models has raised growing concerns regarding their potential misuse in creating harmful or misleading content. In this paper, we introduce MACE, a finetuning framework for the task of mass concept erasure. This task aims to prevent models from generating images that embody unwanted concepts when prompted. Existing concept erasure methods are typically restricted to handling fewer than five concepts simultaneously and struggle to find a balance between erasing concept synonyms (generality) and maintaining unrelated concepts (specificity). In contrast, MACE differs by successfully scaling the erasure scope up to 100 concepts and by achieving an effective balance between generality and specificity. This is achieved by leveraging closed-form cross-attention refinement along with LoRA finetuning, collectively eliminating the information of undesirable concepts. Furthermore, MACE integrates multiple LoRAs without mutual interference. We conduct extensive evaluations of MACE against prior methods across four different tasks: object erasure, celebrity erasure, explicit content erasure, and artistic style erasure. Our results reveal that MACE surpasses prior methods in all evaluated tasks.
- ICLR 2026
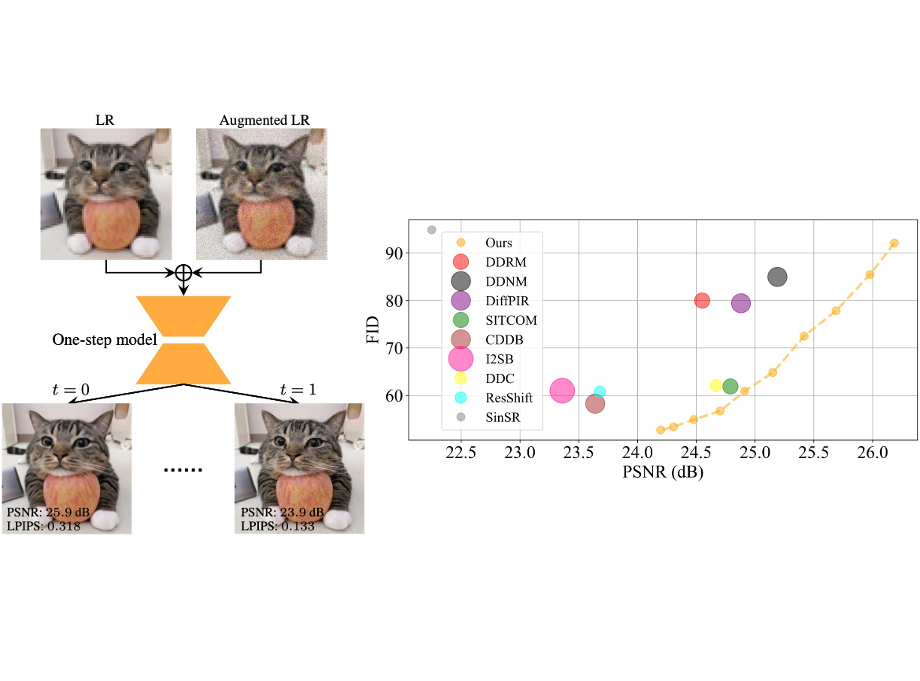 OFTSR: One-Step Flow for Image Super-Resolution with Tunable Fidelity-Realism Trade-offsYuanzhi Zhu, Ruiqing Wang, Shilin Lu, Junnan Li, Hanshu Yan, and 1 more authorPreprint, 2024
OFTSR: One-Step Flow for Image Super-Resolution with Tunable Fidelity-Realism Trade-offsYuanzhi Zhu, Ruiqing Wang, Shilin Lu, Junnan Li, Hanshu Yan, and 1 more authorPreprint, 2024Recent advances in diffusion and flow-based generative models have demonstrated remarkable success in image restoration tasks, achieving superior perceptual quality compared to traditional deep learning approaches. However, these methods either require numerous sampling steps to generate high-quality images, resulting in significant computational overhead, or rely on model distillation, which usually imposes a fixed fidelity-realism trade-off and thus lacks flexibility. In this paper, we introduce OFTSR, a novel flow-based framework for one-step image super-resolution that can produce outputs with tunable levels of fidelity and realism. Our approach first trains a conditional flow-based super-resolution model to serve as a teacher model. We then distill this teacher model by applying a specialized constraint. Specifically, we force the predictions from our one-step student model for same input to lie on the same sampling ODE trajectory of the teacher model. This alignment ensures that the student model’s single-step predictions from initial states match the teacher’s predictions from a closer intermediate state. Through extensive experiments on challenging datasets including FFHQ (256×256), DIV2K, and ImageNet (256×256), we demonstrate that OFTSR achieves state-of-the-art performance for one-step image super-resolution, while having the ability to flexibly tune the fidelity-realism trade-off.


2023
- ICCV 2023
 TF-ICON: Diffusion-Based Training-Free Cross-Domain Image CompositionShilin Lu, Yanzhu Liu, and Adams Wai-Kin KongIEEE/CVF International Conference on Computer Vision (ICCV), 2023
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image CompositionShilin Lu, Yanzhu Liu, and Adams Wai-Kin KongIEEE/CVF International Conference on Computer Vision (ICCV), 2023Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains.

2022
- MTA
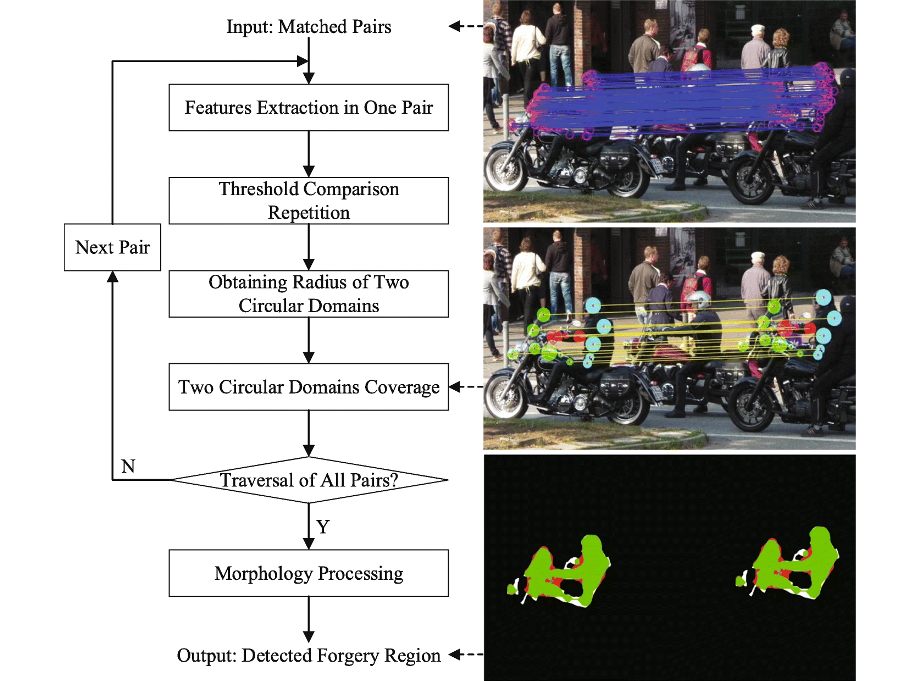 Copy-Move Image Forgery Detection Based on Evolving Circular Domains CoverageShilin Lu, Xinghong Hu, Chengyou Wang, Lu Chen, Shulu Han, and 1 more authorMultimedia Tools and Applications, 2022
Copy-Move Image Forgery Detection Based on Evolving Circular Domains CoverageShilin Lu, Xinghong Hu, Chengyou Wang, Lu Chen, Shulu Han, and 1 more authorMultimedia Tools and Applications, 2022The aim of this paper is to improve the accuracy of copy-move forgery detection (CMFD) in image forensics by proposing a novel scheme and the main contribution is evolving circular domains coverage (ECDC) algorithm. The proposed scheme integrates both block-based and keypoint-based forgery detection methods. Firstly, the speed-up robust feature (SURF) in log-polar space and the scale invariant feature transform (SIFT) are extracted from an entire image. Secondly, generalized 2 nearest neighbor (g2NN) is employed to get massive matched pairs. Then, random sample consensus (RANSAC) algorithm is employed to filter out mismatched pairs, thus allowing rough localization of counterfeit areas. To present these forgery areas more accurately, we propose the efficient and accurate ECDC algorithm to present them. This algorithm can find satisfactory threshold areas by extracting block features from jointly evolving circular domains, which are centered on matched pairs. Finally, morphological operation is applied to refine the detected forgery areas. Experimental results indicate that the proposed CMFD scheme can achieve better detection performance under various attacks compared with other state-of-the-art CMFD schemes.
